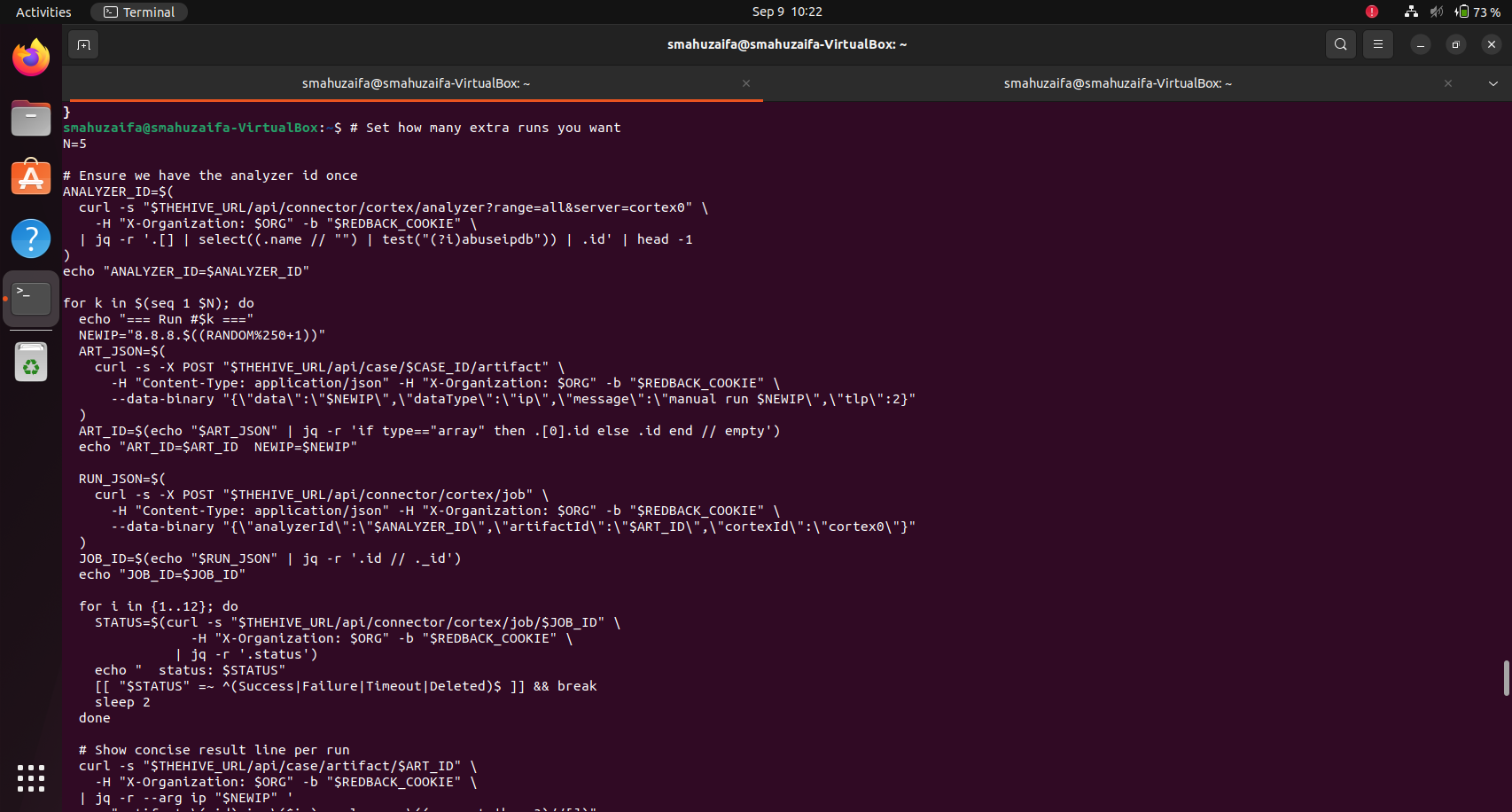
Phase 9 - Cortex Automation
Last updated by: Syed Mahmood Aleem Huzaifa, Last updated on: 23/09/2025
Document Creation: 3 September 2025. Last Edited: 9 September 2025. Authors: Syed Mahmood Aleem Huzaifa.
Effective Date: 9 September 2025. Expiry Date: 9 September 2026.
Objective and context
Goal was to have IP-type observables (artifacts) automatically analyzed by Cortex as soon as they are created in a TheHive case. Because the TheHive UI does not expose the automation feature without a license, the equivalent automation was implemented entirely via TheHive’s REST API. The key components involved were TheHive’s organisation-scoped configuration endpoint for notifications and the connector endpoints that trigger Cortex analyzer jobs for given artifacts.
Step 1: Authentication and storing session cookies
Authentication and storing session cookies began by authenticating to TheHive and capturing session cookies for reuse across API calls. Two sessions were used: an administrator session (to modify organisation configuration, such as notifications) and a regular organisation user session (to create artifacts and trigger analyzer jobs). The pattern is the same for both, using curl -c to write cookies to a file and the appropriate headers. For example:
The provided curl examples for authentication and obtaining session cookies in TheHive are standard and correct:
Admin user authentication to get an admin cookie jar for org-level configuration:
curl -c admin.cookies -X POST "$THEHIVE_URL/api/login" \
-H "Content-Type: application/json" \
-d '{"user":"admin@thehive.local","password":"ADMIN_PASSWORD"}'
Organisation user authentication to get a cookie for normal user actions:
curl -c redback.cookies -X POST "$THEHIVE_URL/api/login" \
-H "Content-Type: application/json" \
-d '{"user":"example@example.com","password":"ENTER_PASSWORD"}'
These commands log into TheHive API by posting JSON with user credentials to the /api/login endpoint. The session cookies created by this login are stored in files (admin.cookies or redback.cookies) which can be reused with curl -b cookie-file in subsequent API calls for authenticated access.
This pattern matches official TheHive authentication API examples where session cookie jars are used for stateful authentication. For API key-based alternatives, token headers can be used instead, but these curl commands provide a cookie-based approach for session reuse and separation of privileges between admin and organization user sessions.
Subsequent API calls consistently included the organisation context and the previously saved cookie. These were sent as headers using -H "X-Organization: REDBACK_COOKIE" or -b "$ADMIN_COOKIE" depending on whether the action was performed in the user or admin session. This approach maintained the correct organization scope and authenticated session state for API requests.
Step 2: Discovering Cortex analyzers available to our server
The Cortex instance named cortex0 was verified and available analyzers enumerated to reliably target one. AbuseIPDB was identified as a suitable analyzer for IP observables. The instance or the server name can be seen in hive settings under the cortex tab
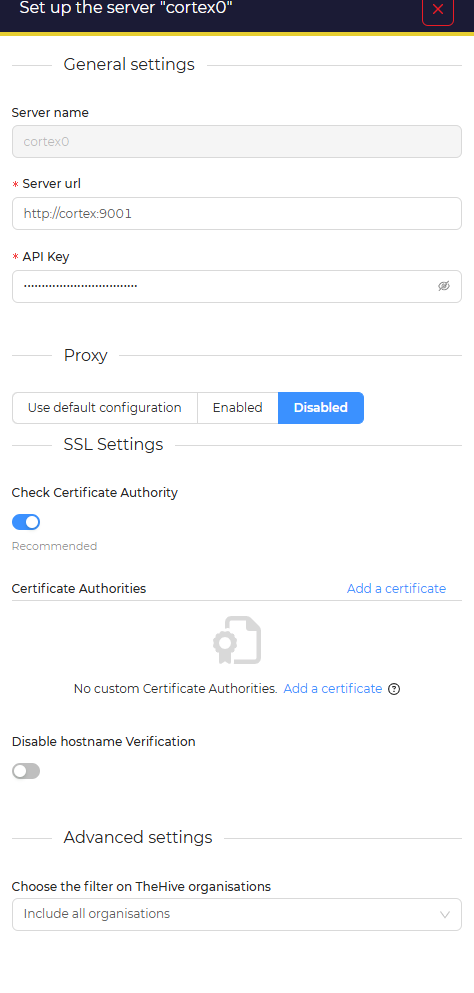
The enumeration was done with the curl command:
curl -s "$THEHIVE_URL/api/connector/cortex/analyzer?range=all&server=cortex0" \
-H "X-Organization: $ORG" -b "$REDBACK_COOKIE" \
| jq '.[0:10] | map({id,name})'
From this list, the analyzer ID was extracted by name matching "abuseIPDB" (case-insensitive) via:
ANALYZER_ID=$(
curl -s "$THEHIVE_URL/api/connector/cortex/analyzer?range=all&server=cortex0" \
-H "X-Organization: $ORG" -b "$REDBACK_COOKIE" \
| jq -r '.[] | select((.name // "") | test("(?i)abuseipdb")) | .id' | head -1
)
echo "ANALYZER_ID=$ANALYZER_ID"
This reliably would return an ID such as 17488d26c141da8992ecf8a3d156b6bb with the analyzer name AbuseIPDB_1_0. This ID is then used to target analyzer jobs for specific IP-type artifacts.
Step 3: Creating a test artifact (observable) in a case
A test artifact (observable) can be created in an existing TheHive case to provide a target for the analyzer. Public IPs were preferred to receive meaningful taxonomy from AbuseIPDB, as reserved/private IP ranges often return uninformative results.
The creation used this curl POST call:
NEWIP="8.8.8.$((RANDOM%250+1))"
ART_JSON=$(
curl -s -X POST "$THEHIVE_URL/api/case/$CASE_ID/artifact" \
-H "Content-Type: application/json" -H "X-Organization: $ORG" -b "$REDBACK_COOKIE" \
--data-binary "{\"data\":\"$NEWIP\",\"dataType\":\"ip\",\"message\":\"manual run $NEWIP\",\"tlp\":2}"
)
ART_ID=$(echo "$ART_JSON" | jq -r 'if type=="array" then .[0].id else .id end // empty')
echo "ART_ID=$ART_ID"
Artifact creation was confirmed by subsequently fetching the artifact during report readings to verify its presence and correctness. This process enabled automated analyzers to run against valid IP observables in the case.
Step 4: Manually triggering an analyzer job (the working endpoint)
The endpoint that successfully scheduled Cortex analyzer jobs for artifacts was:
POST /api/connector/cortex/job
A JSON body containing analyzerId, artifactId, and cortexId is sent. This consistently will return a 201 Created status and produce a job object in “Waiting” status, with the job ID captured via:
RUN_JSON=$(
curl -s -X POST "$THEHIVE_URL/api/connector/cortex/job" \
-H "Content-Type: application/json" -H "X-Organization: $ORG" -b "$REDBACK_COOKIE" \
--data-binary "{\"analyzerId\":\"$ANALYZER_ID\",\"artifactId\":\"$ART_ID\",\"cortexId\":\"cortex0\"}"
)
JOB_ID=$(echo "$RUN_JSON" | jq -r '.id // ._id')
echo "JOB_ID=$JOB_ID"
Step 5: Monitoring the job and retrieving analyzer reports
After scheduling the job, the job resource is polled until the status is no longer “Waiting” or “Running.” The polling request is:
curl -s "$THEHIVE_URL/api/connector/cortex/job/$JOB_ID" \
-H "X-Organization: $ORG" -b "$REDBACK_COOKIE" \
| jq '{id,status,cortexId,cortexJobId,analyzerName}'
When the job reaches “Success,” the artifact is read to access its reports map. TheHive stores analyzer results on the artifact, keyed by analyzer name.
The following command retrieves artifact details and report output:
curl -s "$THEHIVE_URL/api/case/artifact/$ART_ID" \
-H "X-Organization: $ORG" -b "$REDBACK_COOKIE" \
| jq '{id,data,dataType,analyzer_keys:(.reports|keys?),reports:.reports}'
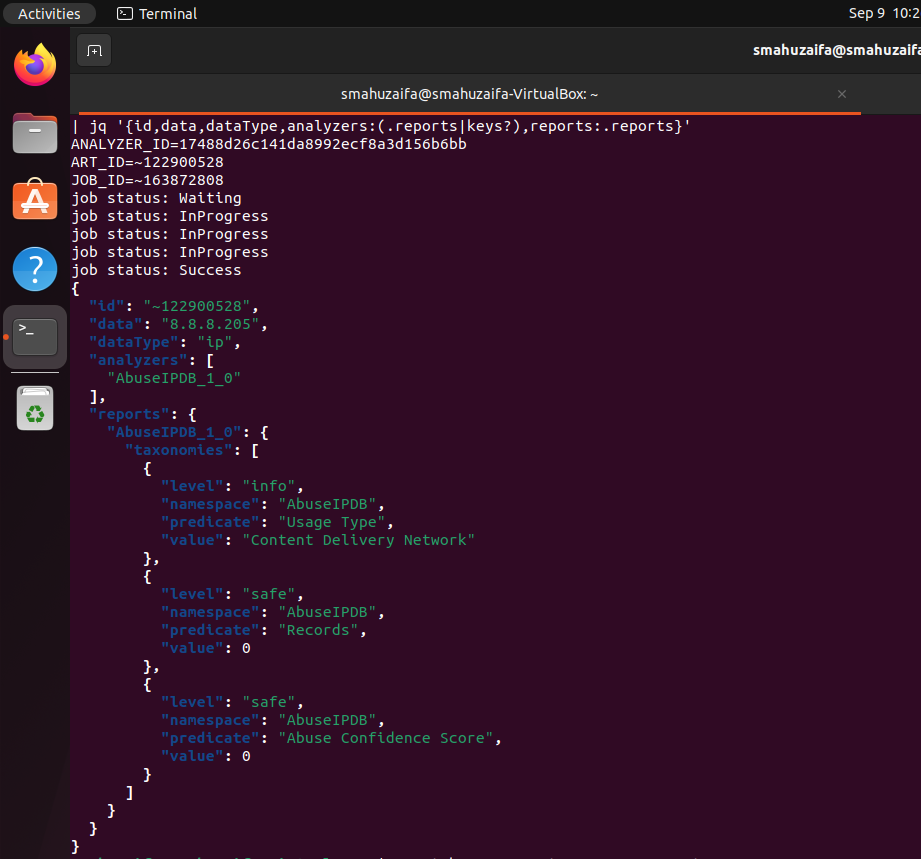 For public IPs, AbuseIPDB taxonomies such as “Abuse Confidence Score,” “Records,” and “Usage Type” appear in the output. For example, 8.8.8.74 returns “Content Delivery Network,” while reserved ranges produce “Reserved” with zero records.
For public IPs, AbuseIPDB taxonomies such as “Abuse Confidence Score,” “Records,” and “Usage Type” appear in the output. For example, 8.8.8.74 returns “Content Delivery Network,” while reserved ranges produce “Reserved” with zero records.
Step 6: Configuring backend automation with organisation notifications
Manual execution confirmed, backend automation is implemented using the organisation configuration path for notifications. The objective is to create a notification that listens for ArtifactCreated events and automatically triggers a Cortex analyzer run for IP selectors. The configuration object resides at:
PUT /api/config/organisation/notification
Attempts to upload placeholder JSON like (...your JSON... ) trigger a BadRequest (“Invalid Json: Unexpected character '.'”) because the payload is not valid JSON. Pasting raw JSON directly into the shell without a heredoc causes bash errors, as keys are interpreted as commands (e.g., “value:: command not found”).
Correct procedure entails writing the JSON to a file using a quoted heredoc and then POSTing that file:
cat > /tmp/redback-notification.json <<'EOF'
{
"value": {
"endpoints": [],
"items": [
{
"name": "AutoRun Cortex IP (cortex0/AbuseIPDB)",
"enabled": true,
"trigger": { "type": "ArtifactCreated" },
"action": {
"type": "RunAnalyzer",
"config": {
"connectorName": "cortex0",
"cortexId": "cortex0",
"selectors": ["ip"],
"analyzers": ["AbuseIPDB_1_0"],
"maxParallel": 2,
"timeout": 600000
}
}
}
]
}
}
EOF
curl -s -X PUT "$THEHIVE_URL/api/config/organisation/notification" \
-H "Content-Type: application/json" -H "X-Organization: $ORG" \
-b "$ADMIN_COOKIE" --data-binary @/tmp/redback-notification.json \
| jq .
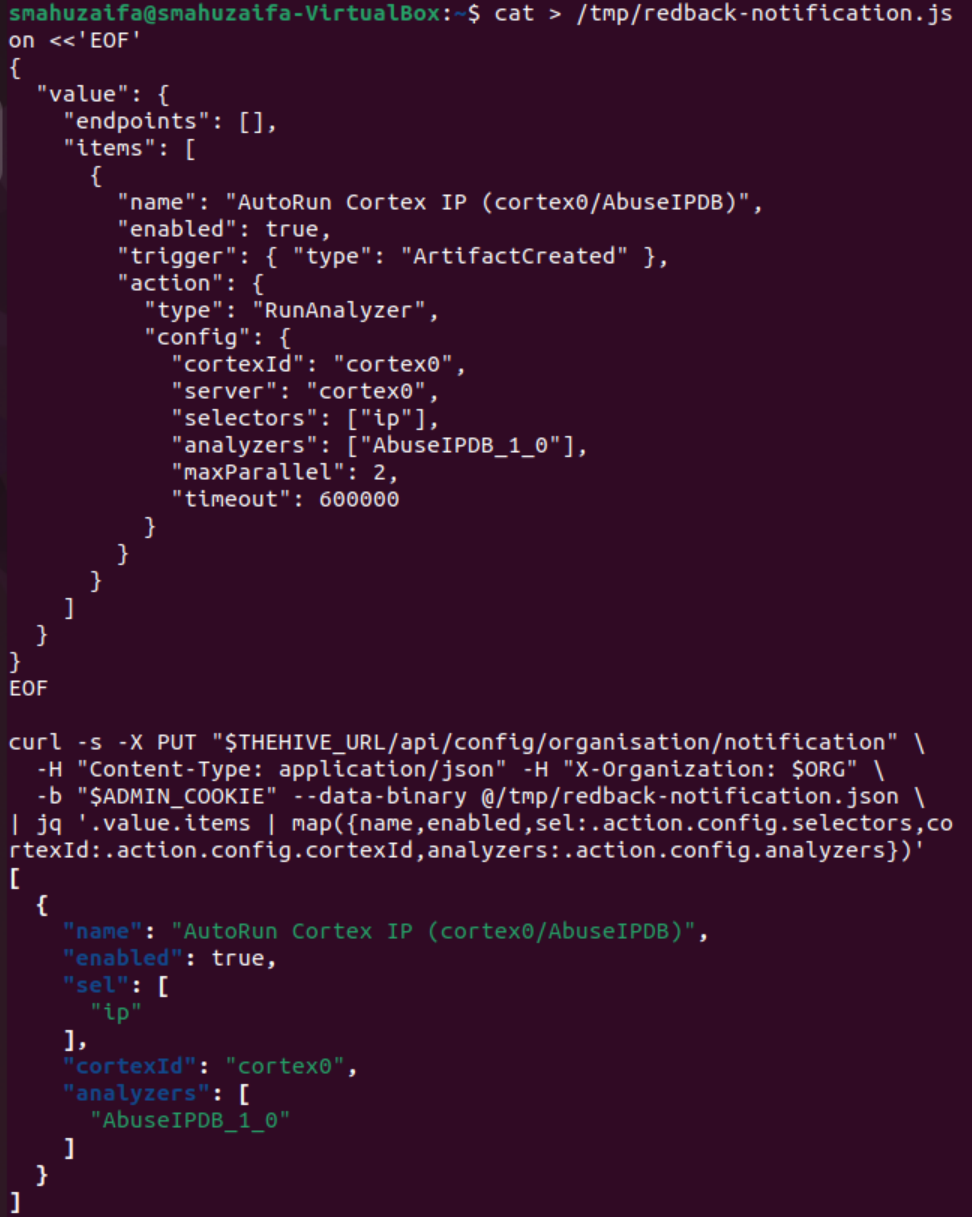 This pattern returns the notification configuration with the single automation rule, confirming persistence.
This pattern returns the notification configuration with the single automation rule, confirming persistence.
Experiments with a wildcard analyzer configuration ("analyzers": [""])* to instruct TheHive to run any matching analyzer for IP selectors against cortex0 yield inconsistent results. PUT requests with the wildcard payload produce a response where .value.items appears null, indicating either silent rejection of the wildcard shape or a missing required key. Reverting to an explicit "AbuseIPDB_1_0" configuration ensures consistent persistence of the automation rule.
Step 7: Validating that the autorun rule fires
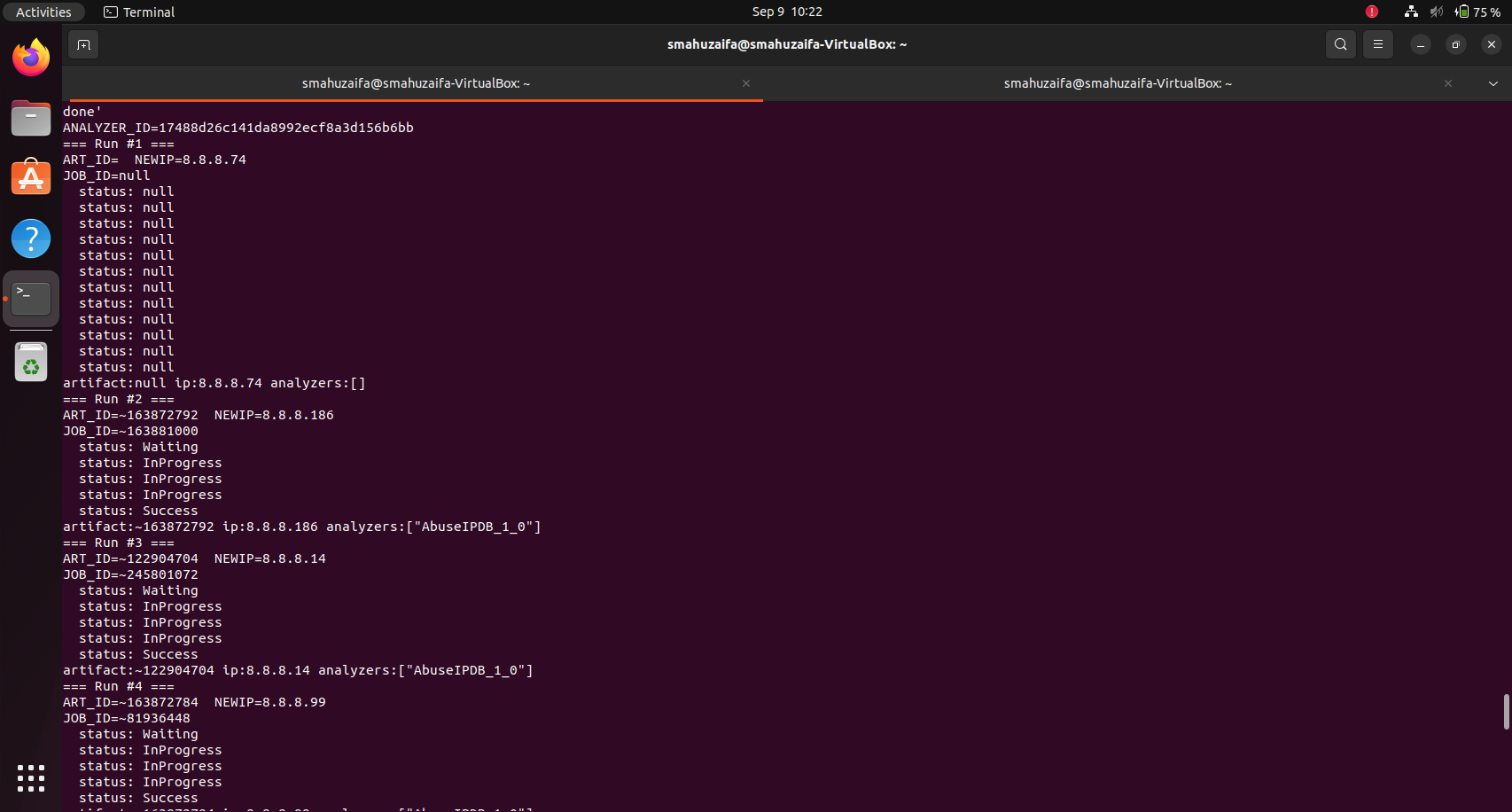
Validation of the autorun rule involves creating new IP artifacts and then checking for jobs associated with each artifact. The job listing command is:
curl -s "$THEHIVE_URL/api/case/artifact/$ART_ID/job?range=all" \
-H "X-Organization: $ORG" -b "$REDBACK_COOKIE" \
| jq '[ .[] | {id,status,cortexId,cortexJobId,analyzerName} ]'
When the rule triggers successfully, each job can be fetched by its ID using /api/connector/cortex/job/JOB_ID to follow its progression to “Success.” The artifact is then read again to observe reports being populated with analyzer output.
During testing, inconsistent response shapes from the jobs list endpoint required safeguards: if the list is empty or not an array, naive .. id indexing in jq raises errors such as “Cannot index string with string 'id'” or “Cannot index object with number.” Checks are adjusted to ensure array type before indexing, preventing false validation failures during job scheduling.
In validation, new artifacts sometimes show no analyzer keys and empty reports immediately after creation; after a brief delay, jobs transition from “Waiting” to “Success,” and artifact reports include AbuseIPDB_1_0 with corresponding taxonomies. This process confirms that both manual and automated Cortex job scheduling works for the same observable type.
Conclusion
The objective was to achieve automatic Cortex analyzer execution in TheHive even though the UI option for analyzer automation was restricted by licensing. To compensate, the automation was implemented using TheHive’s REST API. The workflow began with authentication and session management, where separate administrator and organisation-user sessions were established with reusable cookies to maintain context across API calls. The admin session was needed for organisational-level configuration, while the user session handled artifact creation and analyzer runs.
Analyzer discovery was performed through TheHive’s connector endpoints. This confirmed connectivity to the Cortex server and allowed retrieval of available analyzers such as AbuseIPDB. With this information, analyzers could be targeted reliably by their unique IDs. Test observables were then introduced into cases as IP artifacts. Public IPs were preferred because they produced meaningful taxonomy reports, whereas reserved/private ranges resulted in “Reserved” outputs with empty records.
The manual validation phase relied on directly invoking POST /api/connector/cortex/job, passing parameters such as analyzerId, artifactId, and cortexId. Other legacy endpoints were confirmed non-functional on the deployed version. This step validated the backend path by monitoring job states until they transitioned to “Success,” and fetching analyzer outputs from the artifact’s reports object. Manual execution was essential to prove the correct payload shape, parameter requirements, and result retrieval flow.
Automation was then achieved by configuring organisation-level notification rules via PUT /api/config/organisation/notification. A trigger-action pattern was defined where ArtifactCreated events automatically invoked the RunAnalyzer action for matching IP observables. The rule specified Cortex server identifiers, analyzer names, selectors, and runtime settings. Once deployed, TheHive backend began executing analyzer jobs automatically upon creation of relevant artifacts, replicating the functionality of licensed autorun features.
This approach resulted in a fully automated pipeline: new IP artifacts immediately triggered Cortex analyzers without manual API calls. Initial manual executions served as a diagnostic layer to confirm endpoint behavior, while notification-based automation provided the persistent, hands-off functionality. The key technical success factors were correct authentication handling, using the supported run endpoint with explicit cortexId, and defining valid JSON notification rules scoped to the organisation.
Troubleshooting confirms that omission of cortexId in the job payload results in rejection; inclusion of "cortexId": "cortex0" is always required on this build. Only the endpoint POST /api/connector/cortex/job succeeds, so other legacy endpoints are dropped. JSON payloads for the config endpoint must be complete objects written to disk and sent with --data-binary to prevent shell parsing errors. Defensive jq usage and strategic polling address response variability from job listings. Public IP addresses are consistently chosen as artifacts to yield interpretable AbuseIPDB taxonomies; reserved ranges yield empty or "Reserved" outputs, suitable for technical correctness but limited validation clarity.
Compact Test Sequence:
- A streamlined rerun sequence validates analyzer execution:
- Select AbuseIPDB analyzer ID from cortex0.
- Create a public IP artifact under the target case.
- Trigger the analyzer with POST /api/connector/cortex/job, including analyzerId, artifactId, and cortexId.
- Poll GET /api/connector/cortex/job/JOB_ID until the job state is terminal.
- Read GET /api/case/artifact/ART_ID for analyzer keys in the reports object.
For multiple tests, use a loop to create artifacts, initiate jobs, poll status, and print per-artifact summaries including analyzer report keys.
Current State
This flow enables both manual Cortex analyzer execution and autorun for IP observables as soon as created, all through backend API calls. Reliability is achieved by authenticating once and reusing cookies paired with the organisation header, discovering analyzers using the intended Cortex server name, restricting job creation to POST /api/connector/cortex/job with mandatory cortexId, polling job status via /api/connector/cortex/job/JOB_ID, reading artifact reports, and configuring the organisation-level notification path with a valid ArtifactCreated → RunAnalyzer rule containing connectorName, cortexId, the "ip" selector, and explicit analyzer list such as ["AbuseIPDB_1_0"].